Loss Hunters
The Ames Housing Data Set¶

The Ames Housing Data Set contains information from the Ames Assessor’s Office used in computing the value of individual residential properties sold in Ames, Iowa from 2006 to 2010, as well as the actual eventual sale prices for the properties.
The data set contains information for more than 2900 properties. The data dictionary outlines more than 75 descriptive variables. Some are nominal (categorical), meaning they are non-numerical and lack clear-cut order (Examples: Neighborhood, Type of roofing). Some are ordinal, meaning they are categorical but have a clear order (Example: Heating Quality (Excellent, Good, Average, Poor)). Some are discrete, meaning they are numerical but at set intervals (Year Built, Number of Fireplaces). The rest are continuous, meaning they are numerical and can theoretically take any value in a range (1st Floor Square Feet).
In this project, I have attempted to craft as accurate a model as possible for predicting housing sale prices, using regression techniques, enhanced by feature engineering, feature selection, and regularization. This project was connected to a private Kaggle competition. The Ames data set was divided into a labeled training set, and an unlabeled test set (the labels exist, but are withheld). I aim to accurately predict the withheld sale prices for the test set, based on the features and prices in the training set. This exercise mimics real-world modeling scenarios.
As in many Kaggle competitions, I upload a set of predictions and receive a score that evaluates my performance on a subset of the test set, but evaluation on the entire test set does not take place until the end of the competition. This is significant, because it is possible to overfit your model to the subset of the test set that is being used to generate scores. It is important to prioritize generalizability in a model, instead of just over-tweaking to maximize your accuracy score on the available subset of test data.
Data Cleaning and Processing¶
A lot of data cleaning and data wrangling were involved in preparing the data for analysis and modeling. The full code for this part of the project, and the subsequent editing of the test data to match, can be viewed here in NBViewer.
Among the changes:
- Nominal variables were one-hot-encoded, meaning they were converted into a series of binary variables representing whether each category was true for a given house, yes (1) or no (0).
- Ordinal variables were mapped to numerical format. At times this can be subjective. If one category is significantly better than the others for example, a simple {0,1,2,3} mapping may not be as appropriate as say, {0,1,2,5}. In other cases, it may be most accurate to use something like {-2,-1,0,1,2}. Looking at the counts for each category can be helpful. In cases where the great majority of houses are in one category, it is often sensible to map this category to 0, and indicate other categories as above or below this "standard". In general, using the data dictionary and then individual research as needed is essential here.
- Null or missing values were addressed, typically either by removing properties with missing data or imputing values for the missing data. Some imputations were trivial: Houses with no garage had null values for all garage-related variables, these were imputed easily (Add a 'None' category for 'Garage Type', add 0 for Garage Area, etc.). Other imputations were more complex: Many values were missing for Lot Frontage (i.e.; the length in feet over which a property is adjacent to the street). 0 was not a sensible imputation here, the houses must have some lot frontage. Imputing the mean lot frontage from all houses was an option, but seemed very rough. I chose instead to impute the mean lot frontage from the neighborhood in which the house was located.
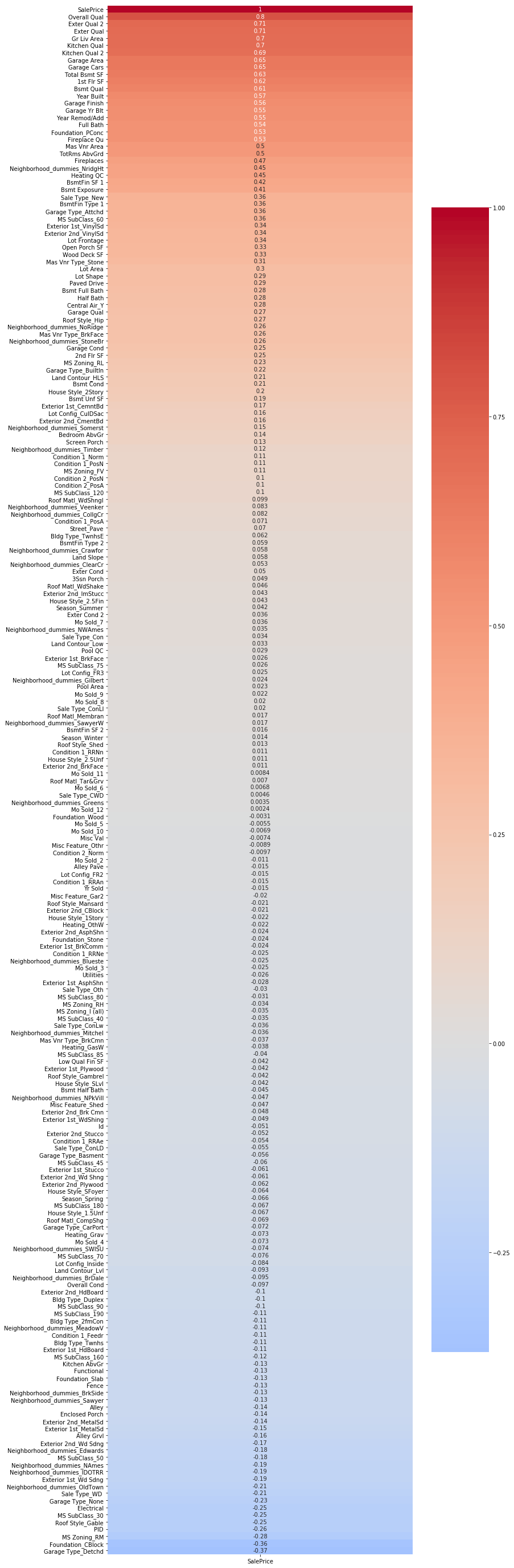
At the end of this process I had a feature table with over 200 variables, and this is prior to any attempts at feature engineering. I have included images of the variables most highly correlated with sale price, both positively and negatively. Keep in mind that these may not all be present among the most predictive variables, as some may be highly collinear and cancel out each other's influence. However we would certainly expect some of these top variables to be among our most predictive variables in any final model.
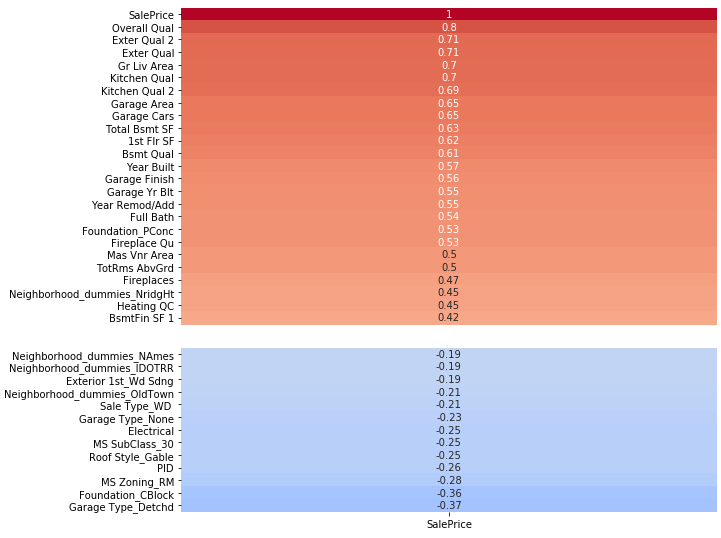
The full heatmap for correlation with sale price can be viewed here.
{kind=link}
Predicting Sale Price with Regression¶
In supervised machine learning, we build a model to predict a target variable from a set of feature variables, by training it on individuals where the target variable is already known. Supervised machine learning problems can be broadly divided into two types of problems: classification problems and regression problems. Classification problems involve trying to predict a categorical target variable - we want to classify new individuals into one of n categories. Regression problems involve trying to predict a continuous target variable - we want to predict the value of the variable for each new individual. As sale price is continuous, this is a regression problem.
Regression analysis essentially involves identifying a mapping function that can be applied to a set of feature variable values to generate an estimate of the true target value for a given individual (i.e.; a prediction). This mapping function is derived by minimizing some loss function that indicates the performance accuracy of the mapping function. The smaller the total loss in our predictions, the closer our predictions are to being correct on average, and the better the performance of the model overall.
The most basic regression technique available to us is linear regression. In this case our mapping function is limited to the form of a straight line:
$$ \begin{eqnarray} y &=& \beta_0 + \beta_1X_1 + \beta_2X_2 + \cdots + \beta_pX_p\\ \end{eqnarray} $$
In this equation, y represents our target prediction for each individual, the different values of X are the values of the feature variables for each individual, and the different values of $ \beta $ are coefficients that represent the magnitude (positive or negative) of each feature variable's influence on our prediction. $ \beta_0 $ represents a constant, the y-intercept of our line; it is also theoretically our prediction for the value of a house where all feature variables = 0.
I will use sklearn's LinearRegression() method to run my linear regression. When I run this, sklearn basically identifies the line of best fit for the data it receives; that is, the line (in multidimensional space) which minimizes loss between the line and the target values - the line which gives the best predictions overall for the training data. The standard loss function used in linear regression is mean squared error (equivalently one could minimize the sum of squared errors) between the predictions (the line) and the actual target values. This is why we often hear this technique referred to as least squares regression; the line of best fit is identified by finding the line that minimizes mean squared error.
The image below depicts a line of best fit for a single feature variable, using the least squares technique. The total area of the squares is the smallest it can be for any straight line.
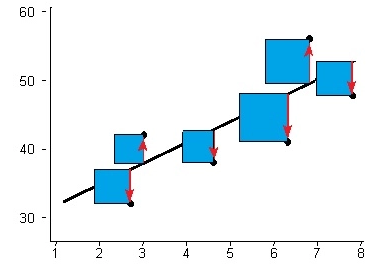
Each time we run LinearRegression(), it will return the best available line of fit from what it receives, plain and simple. This is the first part of minimizing loss. The second part, and really the part that we have control over, involves iteratively improving our model by changing the features that we include when we run LinearRegression(). This can be accomplished by engineering new features to add predictive value, or eliminating redundant and irrelevant features to prevent overfitting. This may seem simple at first blush, but with hundreds of features and the ability to engineer many more, it can be quite complicated. I will go into this below.
After making such changes and establishing a new line of best fit, we can evaluate the performance of our model by checking the R2 Score, which essentially calculates the squared error around our fit line as a percentage of the inherent variance in the data and subtracts that from 1. The R2 score ranges from 0 to 1, and can be thought of as the percentage of variation in the data that is explained by the predictive power of the model. The higher the score, the better the performance.
The ultimate goal here is to iteratively minimize the loss in our model's predictions for new data. To do this, we want to minimize the loss we observe in our training data, while also preserving generalizability. These principles extend to even the most complex supervised machine learning problems.
Import packages and read in cleaned training data¶
#Import basic packages
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
#Import model validation and preprocessing packages
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
#Import regression, metric, and regularization packages
from sklearn.metrics import r2_score, mean_squared_error
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet, RidgeCV, LassoCV, ElasticNetCV
#Jupyter magics (for notebook visualizations)
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
#Set viewing max to 300 variables
pd.set_option('max_columns',300)
#Reads in the cleaned training data
X = pd.read_csv('./datasets/data_clean_final.csv')
Removing Outliers¶
This step should be regarded as optional, but was important to the overall outcome of the Kaggle competition. The data dictionary mentions five observations (houses) that are significant outliers. Essentially these were in-family sales where the sale price greatly underestimates the actual value of the home. The mean squared error for these observations is therefore very large, enough that it significant skews the line of best fit.
The training set contains three of these five values. The test set contains two. However, both are in the withheld portion of the test set. As a result, if you were trying to win the Kaggle competition, it was necessary to leave these outliers in when building your model, so as to account for their influence on the line of best fit. However, leaving them in greatly disrupts loss minimization on the available test subset (that contains no outliers) - in other words, leaving the outliers out allowed you to score much better in the Kaggle rankings.
In my opinion, leaving the outliers in was a flaw in the competition design, because, while instructive about the limitations of loss functions in the presence of outliers, the undersold houses are anomalous cases that take away from the real-world task of trying to accurately assess the price of homes. I worked around the issue by submitting one model with the outliers and one model without (two submissions were permitted). For the purposes of demonstrating iterative improvements in model accuracy, I will proceed here with the outliers excluded. You want to do this now, before manipulating the data any further.
#Removes the three extreme Price by Area outliers in the training set
X.drop(959,inplace=True)
X.drop(1882,inplace=True)
X.drop(125,inplace=True)
#Save csv with no outliers
X.to_csv('./datasets/data_clean_no_outliers.csv',index=False)
#Load the new csv in
X = pd.read_csv('./datasets/data_clean_no_outliers.csv')
Separating the Target and Feature Variables¶
By convention, the target variable (here the Sale Price) is represented by a lowercase y (because it is a single vector), and the feature variables are represented with an uppercase X (because they comprise a matrix).
#Sets target variable (Sale Price) as y
y = X['SalePrice']
#Sets feature variables (everything but Sale Price and Id) as X
X.drop(['SalePrice','Id'], axis=1, inplace=True)
Feature Engineering¶
Feature engineering simply involves creating new variables from those that you already have. These variables can often add predictive value. I did some basic feature engineering during the initial data processing stage; for example, using the month-of-sale variable to create a season-of-sale variable, which I felt could be more relevant.
A more systematic approach to feature engineering is the PolynomialFeatures method in sklearn's preprocessing suite. This generates all possible polynomial combinations of a set of features below a specified nth degree (default = 2). In this case we will generate new features from the square of each feature (some variables may vary quadratically with sale price instead of linearly, in which case these new features may be more predictive than their first-degree counterparts). We will also generate new features from the product of every two features. This type of engineered feature is called an interaction term, because it represents the interaction effect between two variables. If two variables have a synergistic effect on sale price, for instance, then the product of the two features may add considerable predictive value.
#Generates the full polynomial feature table.
poly = PolynomialFeatures(include_bias=False)
X_poly = poly.fit_transform(X)
X_poly.shape
#Adds appropriate feature names to all polynomial features
X_poly = pd.DataFrame(X_poly,columns=poly.get_feature_names(X.columns))
#Generates list of poly feature correlations
X_poly_corrs = X_poly.corrwith(y)
#Shows features most highly correlated (positively) with sale price, poly features included
X_poly_corrs.sort_values(ascending=False).head(20)
#Shows features most highly correlated (negatively) with sale price, poly features included
X_poly_corrs.sort_values().head(5)
Running PolynomialFeatures on our feature set (>200 features to start with) results in over 20,000 features! We can see that some of them are showing higher correlation with sale price than any of our original variables. However, these top poly feature variables will often be highly collinear, and most poly features will be completely irrelevant. The vast majority of features will need to be removed, or our model will end up incredibly overfit to the data. This is where feature elimination comes into play.
Below are plots of some feature variables against sale price. We can see discrete vs continuous variables; outlier houses mentioned by the data dictionary; high vs moderate correlations; and faintly curved plots that point toward a possible polynomial relationship with sale price.
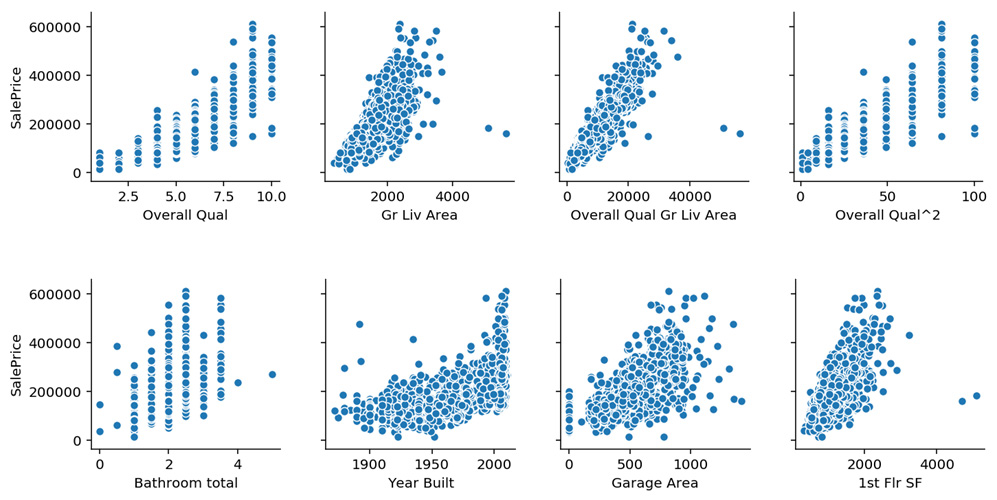
Feature Elimination and Regularization¶
The next step in the process will be whittling down our features.
With a small feature set, feature selection can be done manually. One might remove individual features and observe how the training score is affected. Removing a feature will always reduce the training score some amount, but if that amount is very small, the feature can be discarded in favor of model generalizability. One could continue eliminating the least influential variable until only variables that significantly affect training score remain. However, with a feature set like the one we have here, this approach isn't feasible.
I experimented with different subsets of polynomial features extensively, and ultimately chose to use just two of the highest correlated polynomial features. This seemed to return the best results.
#These are the two polynomial features I ended up including. I decided to just create them manually here.
#Interaction between Overall Quality and Above Ground Living Area (sq. ft)
X['Overall Qual Gr Liv Area'] = X['Overall Qual'] * X['Gr Liv Area']
#Square of Overall Quality
X['Overall Qual^2'] = X['Overall Qual'] * X['Overall Qual']
#I also engineered a feature for total bathrooms, from full baths and half baths.
X['Bathroom total'] = X['Full Bath'] + (0.5 * X['Half Bath'])
#We now have 214 features total.
X.shape
A common issue in modeling is overfitting. This occurs when the model you've designed is too closely matched to the training data, to where it picks up the inherent noise in the training data and mistakes it for meaningful underlying structure. The result is that the model does not generalize well to new data. This typically happens because there are too many parameters or variables involved in the training, and can be resolved by removing some of the complexity while leaving the valuable components intact. The image below shows how an overfit model can minimize training data error so much that it starts to perform worse on new data. The error distance from new data points to the model line will be greater on average in the righthand panel than in the middle panel.
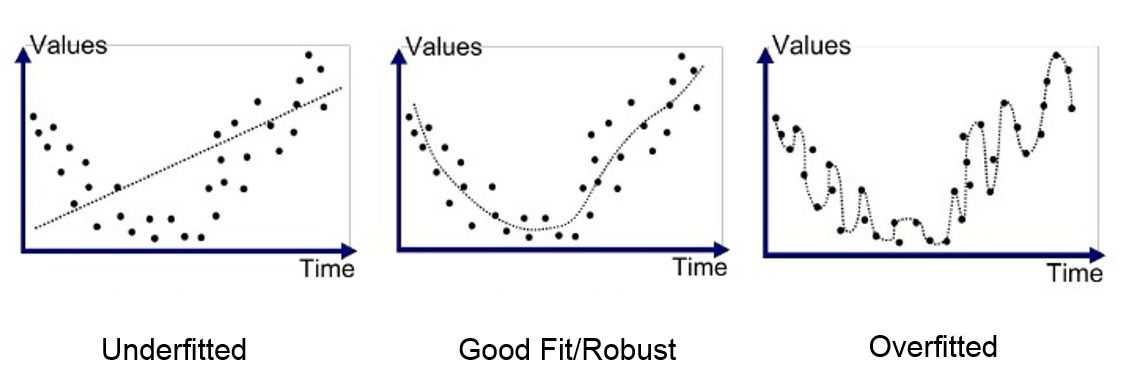
If we use hundreds and hundreds of poly features, we see that the R2 score falls past baseline (~0.85) and further, down to as low as 0.5 or 0.4. This is the result of gross overfitting.
We have chosen instead to remove almost all of the poly features, keeping only the most valuable. But even after this reduction, we still have 214 feature variables, which is quite a lot. A good rule of thumb is to have the number of features be somewhere near the square root of the number of observations. In this case, n=2045 in the training data; the square root of this is ~45. So we can clearly stand to lose some more variables.
One way to reduce overfitting is through regularization. This will be our first defense, and it will be applied as we fit our model. Recall from earlier that the normal loss function when fitting a linear regression (i.e.; the value that LinearRegression() minimizes in order to establish a fit line) is the sum of squared errors (SSE) - the added values of the squared distance between each true sale price and the line's prediction. In regularization, we add an additional term to this loss function, such that the new loss function being minimized is: $$ SSE + \alpha \sum_{j=1}^p \beta_j^2 $$
This extra term is essentially the sum of squared feature coefficients. Including this term in the loss function puts downward pressure broadly on the size of feature coefficient magnitudes, making the model's prediction line less sensitive to features and more generalizable to new data. We are now minimizing error and coefficient size, in balance with each other, rather than just error alone. This prevents overfitting by penalizing coefficient sizes down until we rub up against the core influence in the model. In short, the components of coefficients that represent true signal will remain intact (because these are what keep SSE low), while the components of coefficients that represent noise will be pared down.
The $\alpha$ parameter in the term controls the strength of the regularization. With larger $\alpha$, reducing coefficient size becomes more important to the loss function than reducing sum of squared error. As $\alpha$ approaches 0, the model approaches a traditional least squares regression.
Regularization is a feature elimination technique to a degree, in that less influential features may have their coefficients reduced to at or near zero, while important variables will sustain. However, its effect is a blanket effect that applies to all feature variables at once; there is no inherent selective element. It is better to think of regularization as a model-wide safeguard against overfitting.
Three types of regularization exist: Ridge (L2), Lasso (L1), and ElasticNet. The term shown above is for Ridge. Lasso is similar, except instead of using the squared coefficient to get magnitude, it uses the absolute value. One advantage of Lasso is that it can reduce coefficients all the way to zero, eliminating features entirely, which Ridge cannot do. ElasticNet is essentially a weighted combination of Lasso and Ridge. A parameter called the L1 Ratio determines which is predominant. L1 ratio of 0 = Ridge. L1 ratio of 1 = Lasso. Anything in between is a combination of the two. We will employ ElasticNet, as shown later, when we fit our model.
In addition to using regularization, I experimented with manually removing variables that were poorly correlated with sale price. I found that removing about 100 variables from the 214, prior to fitting a model with regularization, produced the best scoring results. Removing more than this appeared to go too far, beginning to weaken performance and introduce bias by starving the model of information.
I also saw improvement from iteratively fitting models, removing variables with insignificant coefficients, and re-fitting. This seemed like a sensible way to reduce feature complexity. This at times included variables with relatively high correlations with sale price. This was all in the final stages of modeling.
#Removes the 100 features least correlated with sale price.
#Specifically, this code makes a sorted list of the magnitude of all feature correlations with sale price,
#drops the 100 smallest correlations, grabs remaining feature names, and condenses feature set to only those features.
features_keep = list(abs(X.corrwith(y)).sort_values(ascending=False)[:-100].index)
X = X[features_keep]
#This additional drop list is based on me then iteratively fitting models and removing features that
#failed to meet a threshold for predictive influence (coefficient magnitude) after regularization.
X.drop(['Exterior 1st_CemntBd', 'Foundation_CBlock', 'Neighborhood_dummies_Timber', 'Alley', 'Electrical',
'Lot Config_Inside', 'Neighborhood_dummies_BrDale', 'Exterior 2nd_HdBoard', 'Exterior 1st_MetalSd',
'Neighborhood_dummies_NAmes', 'Neighborhood_dummies_BrkSide', 'House Style_2Story', 'MS SubClass_50','Roof Style_Hip',
'Neighborhood_dummies_Sawyer', 'Mas Vnr Type_BrkFace','MS SubClass_60','Fence','Foundation_Slab','Exterior 2nd_CmentBd',
'Bedroom AbvGr','Lot Shape','Exterior 2nd_MetalSd','Garage Type_BuiltIn'], axis=1,inplace=True)
Train Test Split and Standard Scaler¶
Now to the process. The typical workflow for building a model based on supervised learning from a training set involves creating what is called a train/test split. Essentially we are splitting the training data into a training bloc and a testing bloc. We will train the model on the houses in the train bloc and then test it on the houses in the test bloc. This test bloc is not to be confused with the test set for the Kaggle competition - think of that test set as equivalent to actual real world data that one might want to predict. This test bloc is a subdivision of our training set that we will use to validate our training process.
When we run train_test_split on our X feature set and our y target variable, it will create the train and test blocs by randomly splitting the observations in the dataset into one or the other. We can set the relative size of the train and test blocs, but the default is a train bloc of 75% of the data and a test bloc of 25%.
The point of creating this train/test split is to make sure that our model generalizes well to new data. If we simply train on the entire training data set, then our model will likely become overfit to the particular data in that set, such that it may actually be worse at predicting the sale price for new houses. Once we are satisfied that the model we've built generalizes well to new data, then we can train it on the full training set (including our test bloc) to incorporate as much information as possible into the model before running it on the test set and submitting the predictions to Kaggle.
Once we have made our train/test split, we need to standardize our data. This means converting the values of every feature (example, 1st floor square footage) into standardized z-scores, having mean of 0 and unit variance. Each value is essentially represented by how many standard deviations it is from the mean value for the feature. This brings all our features onto the same scale. Regularization requires standardized data to function properly. Otherwise, features using units with large scales will throw off the function of the penalty term.
To standardize our data, we use StandardScaler(). We fit to our training bloc, transform it, and then transform the test bloc to match. We only need to standardize our feature data. The sale price data will remain as is.
#Train test split (Random state is set for reproducibility)
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=19)
#Standardize data
ss = StandardScaler()
X_train_sc = ss.fit_transform(X_train)
X_test_sc = ss.transform(X_test)
Cross Validation and GridSearchCV¶
Once we have our standardized train and test blocs, we can proceed to fitting a model. The critical tool in model evaluation is cross-validation. Fitting a model once is often unreliable. Depending on the model, and the way your data has been split into training and test sections, performance score can vary considerably from fit to fit, sometimes ranging from, say, 0.6 to 0.9. This is insufficient to move forward with. In order to make results more reliable, the training set is split randomly into k equal-sized subsections (typically 3 or 5), called folds. Here we will use 5 folds. Instead of doing a single fit, cross-validation does 5 fits, one for each fold. Each fold serves as the test section exactly once. Cross-validation then returns the mean of the 5 R2 scores. This mean score gives a much more accurate sense of how well the underlying model performs than a single fit.
Our approach, then, would be to tweak our model with whatever changes we want to try, then run cross_val_score() with ElasticNet() (the equivalent of LinearRegression(), but with ElasticNet regularization), and see how the model scores over five folds. However, there is more to consider. Regularization, as we have mentioned, involves hyperparameters. In our case, we need to decide on an $\alpha$ to use (regularization strength), and an L1 ratio (balance of Ridge vs Lasso in the ElasticNet). It's difficult to say which values will result in the best performance. It would be tedious to run cross_val_score over and over with different hyperparameter combinations.
Instead, we use the GridSearchCV() method (ElasticCV could also be used in this case) to fit our model. GridSearchCV has cross-validation built-in. Given the values that we want to test for each hyperparameter, GridSearchCV will iterate through each possible combination of hyperparameters and obtain the cross-validation score for some method, in this case ElasticNet. GridSearchCV will choose the best-performing model of all the combinations for the final fit. This may be a little time-consuming, depending on the size of the dataset, as GridSearch needs to fit k models for every hyperparameter combo, which can very quickly run into hundreds of fits in total. However, this allows us to concentrate our entire fitting process into a single execution, and gives us a fairly unbiased approach to identifying the best hyperparameter values. We can supply a comprehensive range of values for a hyperparameter, and then narrow this range in another GridSearch if we feel it is necessary. After fitting is complete, the GridSearch output has a .score_ method that allows us to evaluate R2 score on the test bloc.
This is the essential process of testing our model ideas. It is important to understand that, while I am doing everything only once here, this process of:
- tweak model
- train/test split
- GridSearch with regularization and cross-validation
- evaluate model score on test bloc
is repeated many times during the iterative process of informed trial and error that is model building.
Logarithmic Transformation of Sale Prices (y)¶
Before we proceed to fitting, we need to make one more tweak. We spoke earlier about how the actual work of model building in many ways boils down to changing the features we include when fitting a model. We discussed feature engineering and feature elimination, however there is a third approach. We can also transform existing features - including the target variable itself.
The distribution of housing sale prices tends to be strongly right-skewed, meaning there is a main concentration around the median house price, and then a small number of expensive homes that stretch the distribution upward, so that it is not normally distributed. It is often a good idea to normalize the distribution of your target variable in these cases, as skewed targets often lead to biased predictions at certain values - at larger sale prices, for instance, our model may underpredict the actual prices of homes. A good way to normalize right-skewed distributions is with a logarithmic transformation. Logarithmic functions are inverse to exponential functions. They have the effect of reducing wide-ranging values over orders of magnitude to a small scope.
The plots below illustrate what the logarithmic transformation achieves. At left is the distribution of sale price in our training set. At right is the same distribution after logarithm transformation. In addition to reducing scale, the logarithm condenses large values toward the mean, while spreading out smaller values. This has the effect of normalizing the sale price distribution.
![]()
It is probably a good idea to log transform any major feature variables that share the same right skew as the target variable. If we don't, then we will lose some predictive power in those variables, which will no longer correlate as well. However, a cursory look at the distributions of top variables indicates that this is for the most part not an issue.
#Log transformation of target variable
y_train_log = np.log(y_train)
y_test_log = np.log(y_test)
It isn't necessary to do this after the train test split, however it will make things simpler later if we leave y_test intact with the normal sale prices.
GridSearch with ElasticNet¶
Here, finally, we will actually fit our model and evaluate its performance! As mentioned above, we will use GridSearchCV with ElasticNet.
#Specify desired values to try for each hyperparameter
param_grid_1 = {
'alpha':[.1,.3,.5,1,5],
'l1_ratio':[0,.3,.5,.7,1]
}
#Instantiate GridSearchCV with ElasticNet, the parameter values, and 5-fold CV.
gs = GridSearchCV(ElasticNet(),param_grid_1,cv=5,verbose=1)
#Fitting with the scaled X_train and the transformed y_train
gs.fit(X_train_sc,y_train_log)
#Returns the best parameters
gs.best_params_
After trying 25 different hyperparameter combinations (125 fits total), GridSearchCV returns the model with $\alpha$ = 0.1, and L1 ratio = 0. So this is pure Ridge regression, with a relatively small penalty strength. Let's check how it performs.
#Returns the R2 score of the best parameters
gs.best_score_
gs.score(X_test_sc,y_test_log)
Our model's R2 score is close to 0.93 on the unseen data! In other words, our model explains almost 93% of variation in sale price in the test bloc data, which it has not trained on. There is no evidence of overfitting, as the training score is lower than the test score, around 0.91. This result is well above baseline regression performance. From an accuracy standpoint, this is a solid model. Now let's look at some of the feature coefficients.
#creates table of all feature variables and their model coefficients
coef_table = pd.DataFrame(gs.best_estimator_.coef_, index=X_train.columns, columns=['Coefficients'])
#creates column with coefficient magnitudes
coef_table['Magnitude']=abs(coef_table['Coefficients'])
#sorts features by coefficient magnitude (i.e.; predictive power) and shows top 25 most influential features
coef_table.sort_values('Magnitude',ascending=False).head(25)['Coefficients']
The top predictive features that we see here are very plausible. At the very top, we have above ground living area, overall quality, overall condition, basement living area. Then: Properties zoned as residential low density are associated with higher price; functional deficits correspond to lower price; lot area; houses built more recently sell higher. After that, central AC, high quality heating, finished basements and paved driveways are in the next tier of factors that predict high price. We also see the influence of a few neighborhoods, for better or worse ("Location, location!"). The model certainly seems sound.
Plotting Predictions against Actual Values¶
Finally, we want to plot our predicted sale prices for the test bloc houses against the actual prices, to see how the model performs on different segments of the data. In a perfect model with R2 score = 1.0, predicted values would equal actual values, and we would expect a straight diagonal line (x=y). We will overlay this ideal line on the scatterplot.
#Generates a list of the model's predictions for the test bloc
preds = gs.predict(X_test_sc)
#Plots predicted values against actual values in the train/test split.
plt.figure(figsize=(10,8))
plt.scatter(np.exp(preds),y_test,marker = '+')
plt.xlabel('Predicted values')
plt.ylabel('Actual values')
#Plots x=y line
plt.plot([0,np.max(y_test)],[0,np.max(y_test)], c = 'k');

The model certainly looks very strong here. There are very few poor predictions, and perhaps no real outliers. We don't appear to be significantly underpredicting or overpredicting on any stretch of data. What is also impressive is the relative equality of error variance across sale prices. Though there appears to be some increase in error variance with sale price, it is quite mild compared to initial iterations with basic regression. This property of equal error variance is termed homoscedasticity, as opposed to heteroscedasticity, and it is important here, because homoscedasticity of errors is actually one of the fundamental assumptions necessary for linear regression to be unbiased.
Re-train on Full Training Set and Submit Test Set Predictions¶
Once we are satisfied with the performance of our model on the test bloc, we can use the same parameters and re-fit (or re-train) our model on the entire training set (train bloc and test bloc) to give it as much learning data as possible, then use that model to generate our predictions for the Kaggle test set, and submit the list to the competition.
#Initializes model for whole training set
gs_full_trainset = gs.best_estimator_
#Applies StandardScaler normalization to whole training set
X_sc = ss.fit_transform(X)
#Log transformation of sale price for whole training set
y_log = np.log(y)
#Re-fits the model
gs_full_trainset.fit(X_sc,y_log)
#Scores the model (training score only, of course)
gs_full_trainset.score(X_sc,y_log)
The training score has increased from .908 to .928; the model should be more accurate now.
The submission format is particular to the competition, but the important thing to remember is we must use np.exp() on our predicted sale prices to reverse the log transformation before submitting anything! Otherwise we will submit a bunch of laughably low values.
#Load in the Kaggle test set with cleaning changes applied
testset = pd.read_csv('./datasets/test_clean_final.csv')
#Drops Id column like we did earlier to the training set.
#Recall that there is no SalePrice info in the test set.
testset.drop('Id',axis=1,inplace=True)
#Apply feature engineering changes to test set (This layout allows easy iterative manipulation)
def changes_to_testset(X):
X['Overall Qual Gr Liv Area'] = X['Overall Qual'] * X['Gr Liv Area']
X['Overall Qual^2'] = X['Overall Qual'] * X['Overall Qual']
X['Bathroom total'] = X['Full Bath'] + (0.5 * X['Half Bath'])
changes_to_testset(testset)
#Apply feature elimination changes to test set
testset = testset[features_keep]
testset.drop(['Exterior 1st_CemntBd', 'Foundation_CBlock', 'Neighborhood_dummies_Timber', 'Alley', 'Electrical',
'Lot Config_Inside', 'Neighborhood_dummies_BrDale', 'Exterior 2nd_HdBoard', 'Exterior 1st_MetalSd',
'Neighborhood_dummies_NAmes', 'Neighborhood_dummies_BrkSide', 'House Style_2Story', 'MS SubClass_50','Roof Style_Hip',
'Neighborhood_dummies_Sawyer', 'Mas Vnr Type_BrkFace','MS SubClass_60','Fence','Foundation_Slab','Exterior 2nd_CmentBd',
'Bedroom AbvGr','Lot Shape','Exterior 2nd_MetalSd','Garage Type_BuiltIn'], axis=1,inplace=True)
#Scale test set
testset_sc = ss.transform(testset)
#Generate model predictions for test set
predictions = gs_full_trainset.predict(testset_sc)
#Reverse log transformation of sale prices
predictions = np.exp(predictions)
#Create submission csv in proper format
testset['SalePrice'] = predictions
testfile = pd.read_csv('./datasets/test_clean_final.csv')
testset['Id'] = testfile['Id']
submission = testset[['Id','SalePrice']]
submission.to_csv('./datasets/kaggle_submission.csv',index=False)
#View submission
submission.head()
Conclusions¶
By using feature engineering, feature elimination, regularization, and (where applicable) target variable transformation, we can reduce loss and greatly improve the performance of even a basic model like linear regression.
The Importance of Outliers¶
As I mentioned earlier on, the five outlier houses mentioned in the data dictionary had a significant effect on final model performance. I submitted one model with the outliers excluded, which allowed me to score accurately on the ranking board (and have a sense of how well my iterative changes were performing on the pure data), and one model with the outliers included, because I suspected this would be necessary to do well in the final evaluation on the whole test set.
85 participants submitted models to the competition. My model without outliers ranked 2nd in accuracy on the subset of the test data used for scoring, which contained no outliers. My model with the outliers included would have ranked in the low 20s at this point (only top scores were ranked).
In the actual competition results, evaluated on the entire test set, which included two of the outliers, my model with outliers was my top performing model, and ranked 5th overall. Clearly, the influence of the outliers on mean squared error was predominant, but the underlying model appears to have been sound. I was the only participant ranked in the top 10 on both boards.
Interpretability of Linear Regression¶
Linear Regression may be a basic method when it comes to predictive accuracy. But predicting the sale price of a house isn't everything. In fact, knowing what factors influence the selling price of a house may well be more valuable than the predictions themselves.
One of the great advantages of linear regression relative to more complex techniques is its interpretability. Not only can we identify which features exert the most influence on our predictions, we even have the relative magnitude and direction of their influence, as given by the associated coefficients. This information can be very useful. When using more complex and high-powered modeling techniques like gradient boosting or neural networks, we will tend to get higher predictive accuracy, but much more limited interpretability. This is one of the great trade-offs in data science.
As an example, we might have considered using something like principal component analysis with these data, as a way of reducing the dimensionality of the polynomial features and systematically gleaning the value in all of the multicollinear interaction terms heavily correlated with sale price. Doing this would greatly reduce feature complexity and surely improve the accuracy of the model, but we would also lose all interpretability. The composite features would be a palimpsest. Instead, we chose to manually select a few top poly features by looking at correlation, coefficient magnitudes, and trying to employ common sense or domain knowledge to leave out anything that was likely to be redundant.